
I am a partner at BeingBeyond, a startup focused on building foundation models for embodied intelligence, where I lead research on robotics post-training and infrastructure. I work closely with Sipeng Zheng and Chaoyi Xu. I received my Ph.D. in Computer Science from Peking University in 2026, where I was advised by Prof. Zongqing Lu. Before that, I received my Master's degree in Computer Science from Tsinghua University in 2022 and my Bachelor's degree in Mathematics from Nankai University in 2019. My research interests lie in Foundation Models, Reinforcement Learning, and Robotics. For more details, please see my CV or Chinese CV.
Selected Publication
(For the full publications, please see my Google Scholar.)
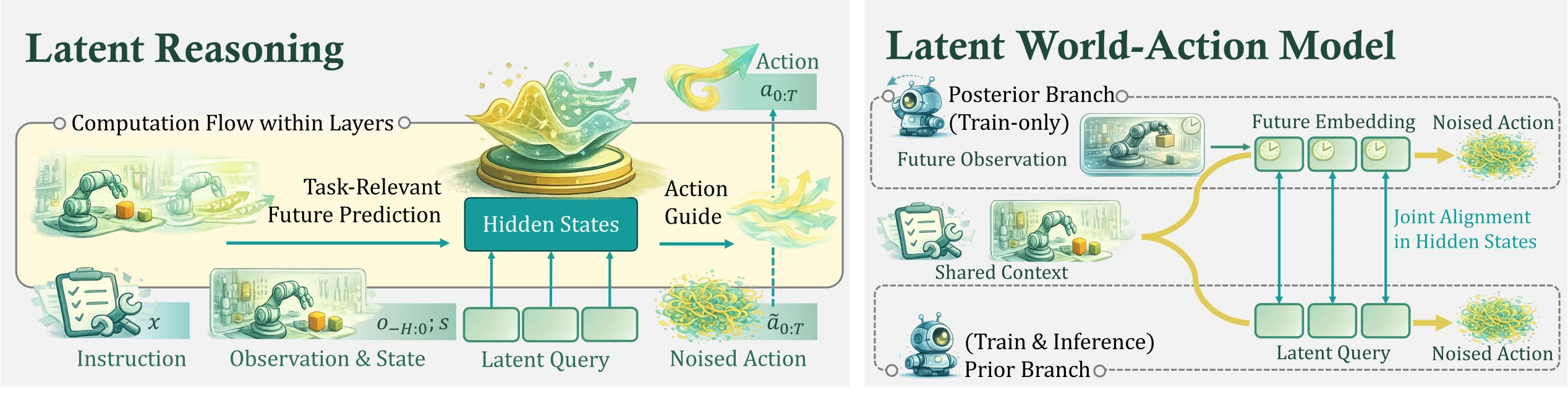
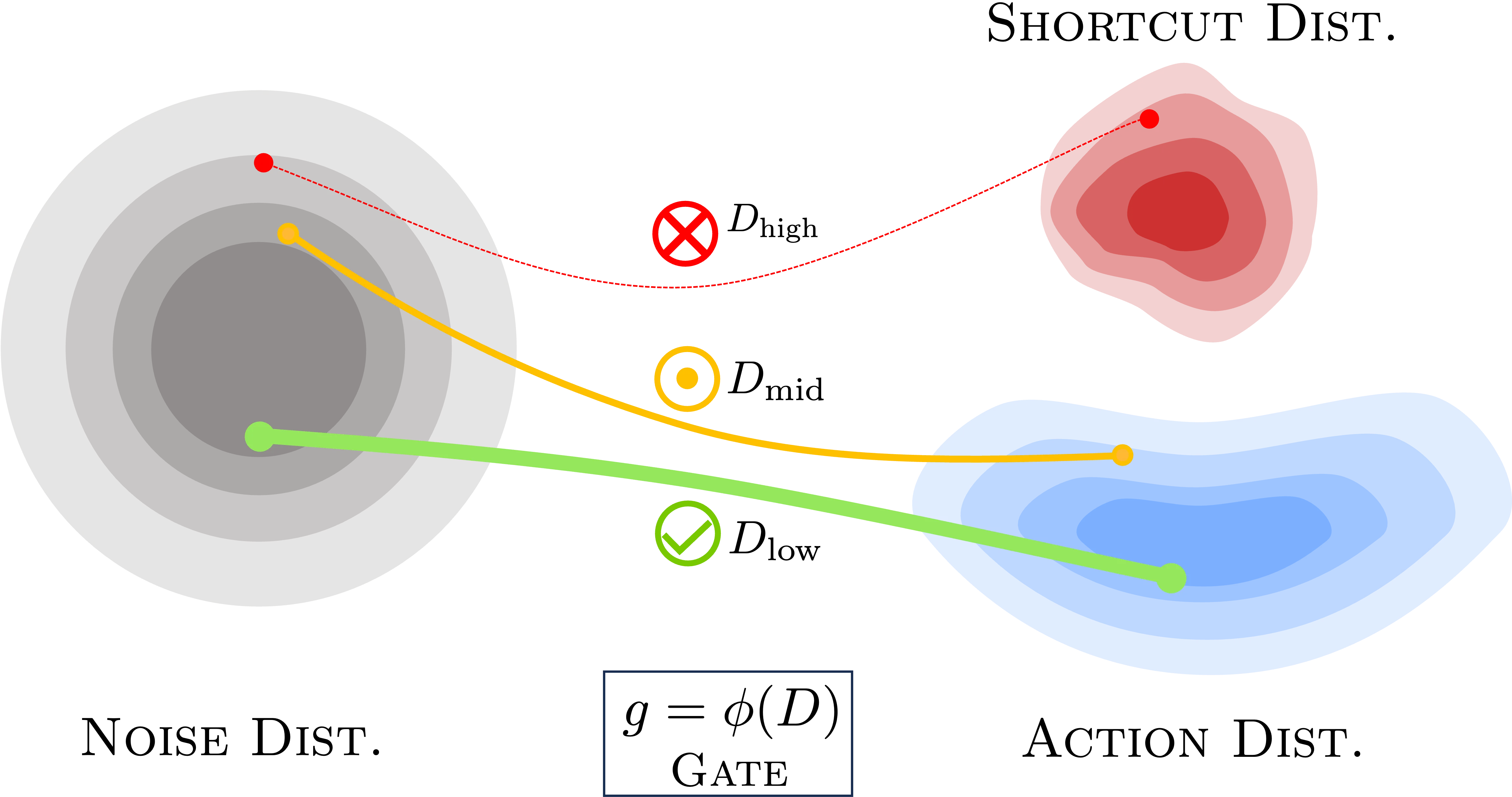
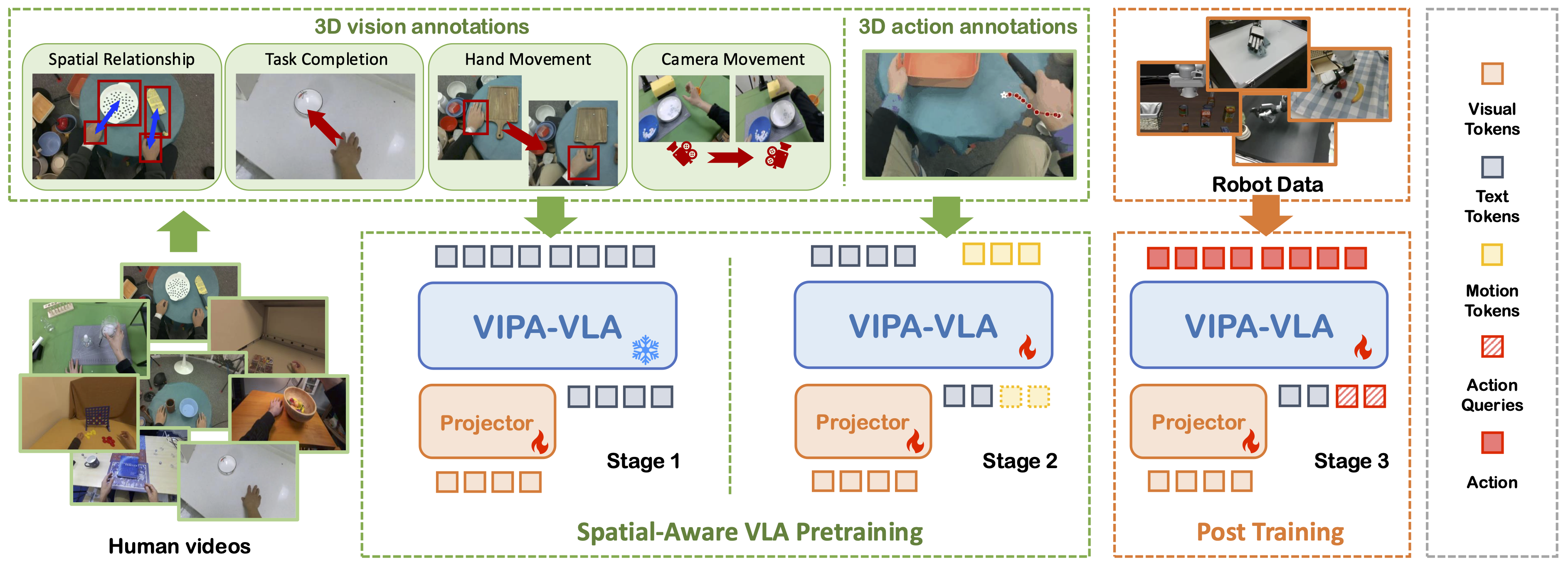
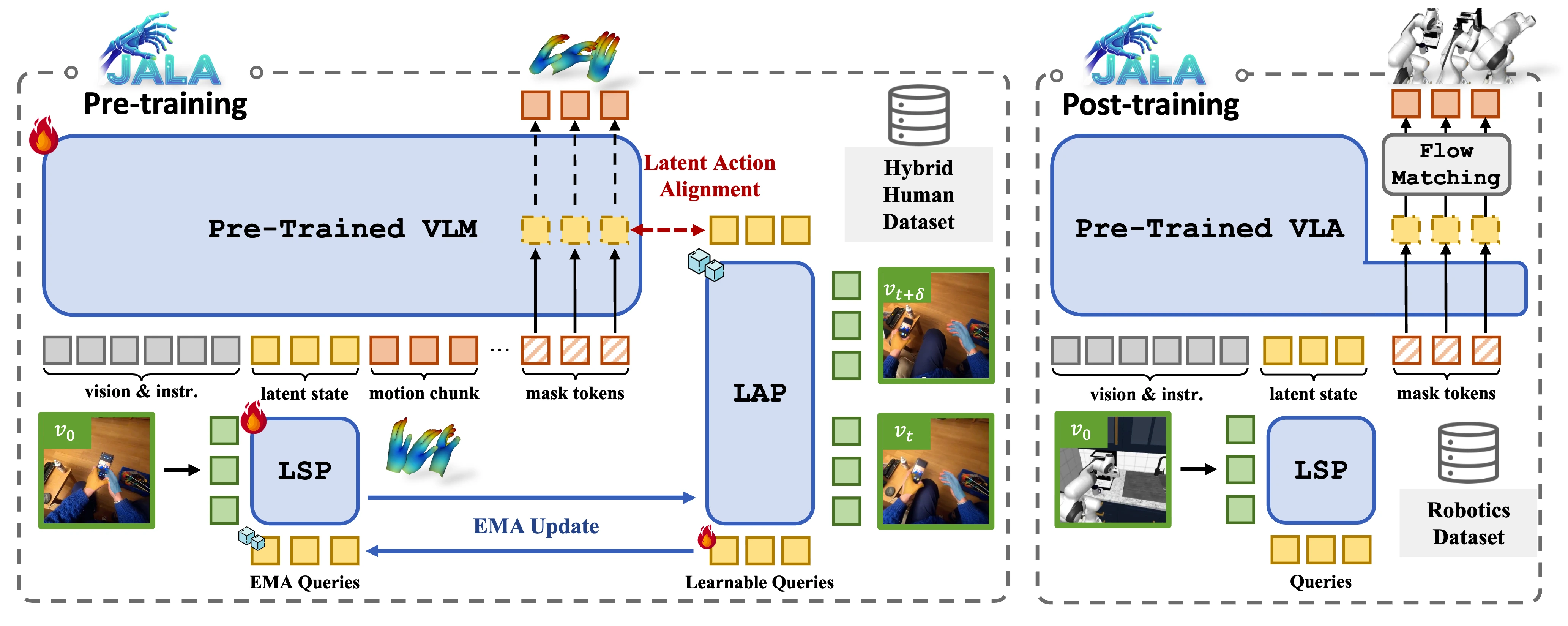
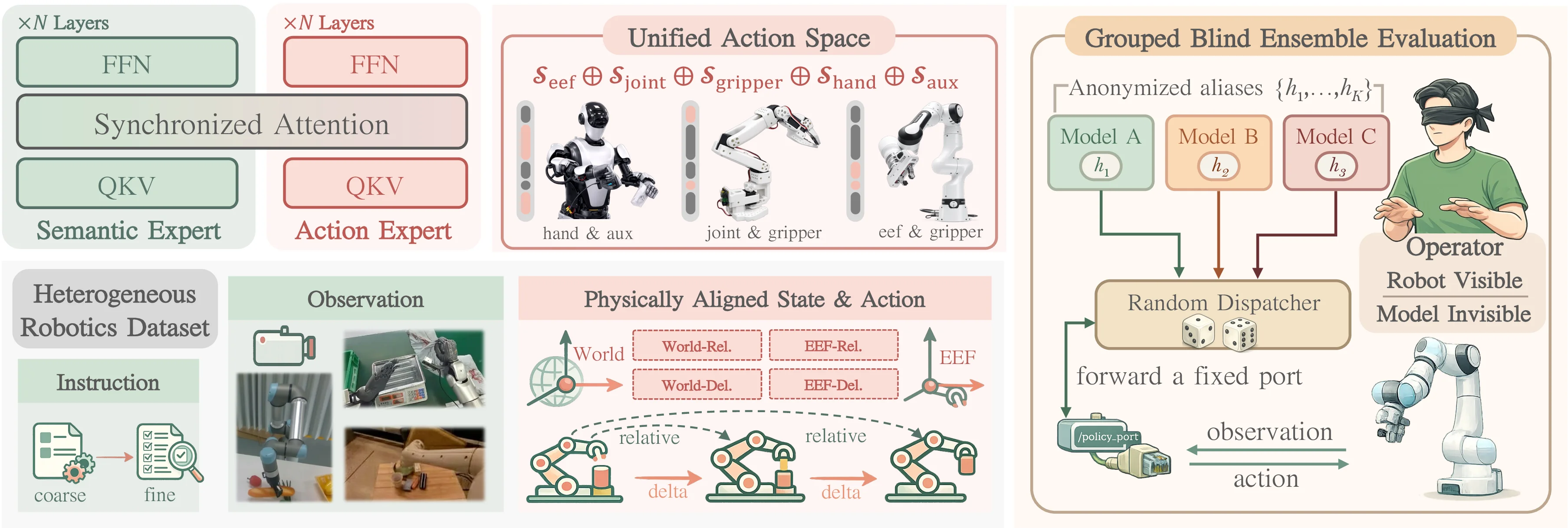
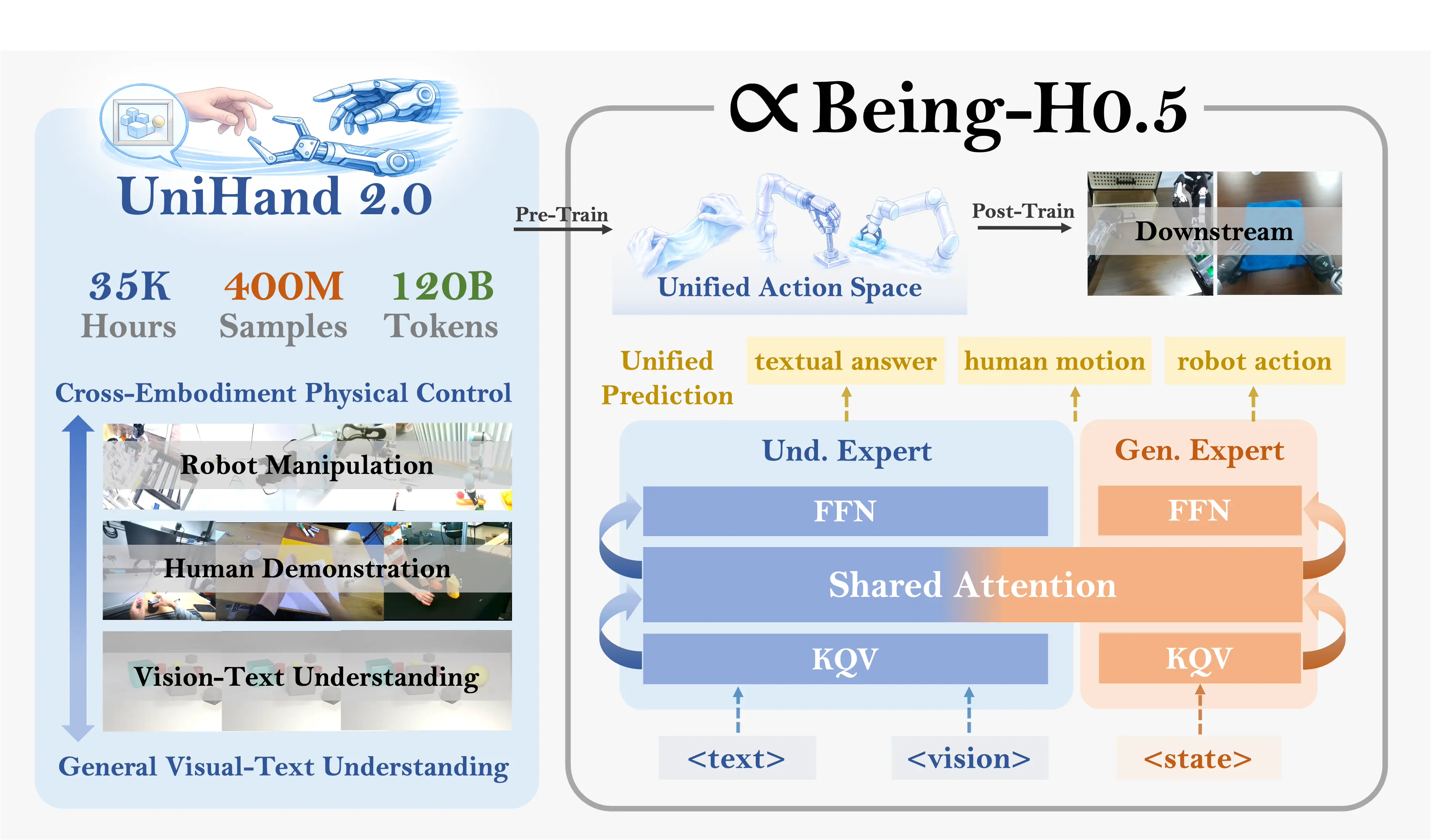
Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
Being-H0.5 is a foundational VLA model that scales human-centric learning with a unified action space to enable robust cross-embodiment robot control.
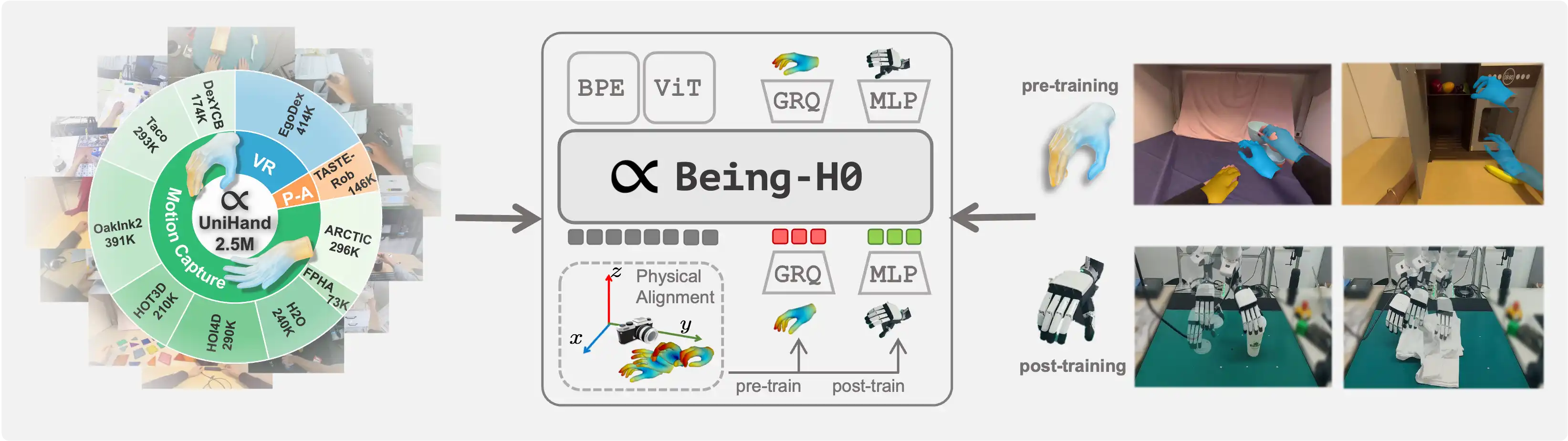
Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos
We introduce Being-H0, the first dexterous Vision-Language-Action model pretrained from large-scale human videos via explicit hand motion modeling.
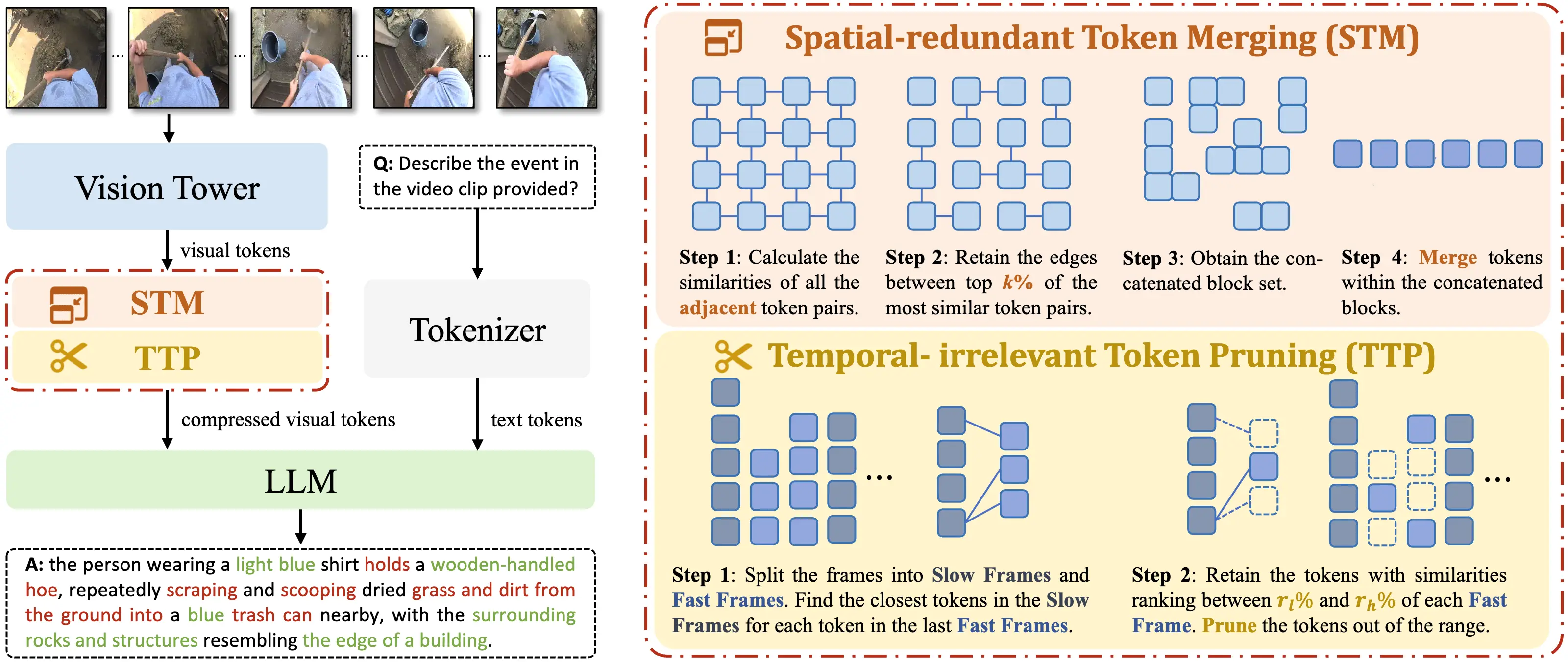
OpenMMEgo: Enhancing Egocentric Understanding for LMMs with Open Weights and Data
OpenMMEgo enhances egocentric video understanding through a multi-level synthetic dataset, semantic-aware visual token compression to handle viewpoint shifts, and curriculum learning for stable training.
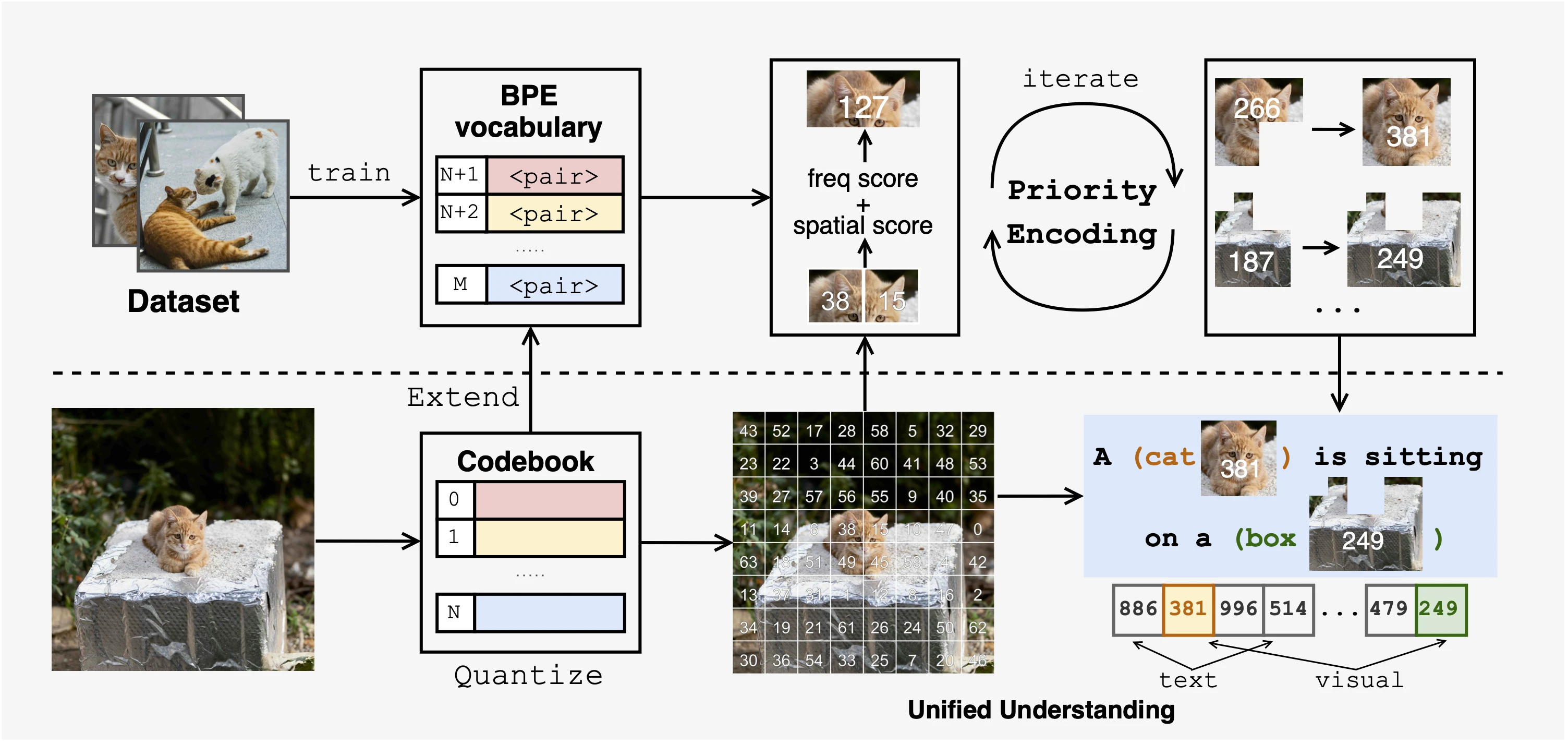
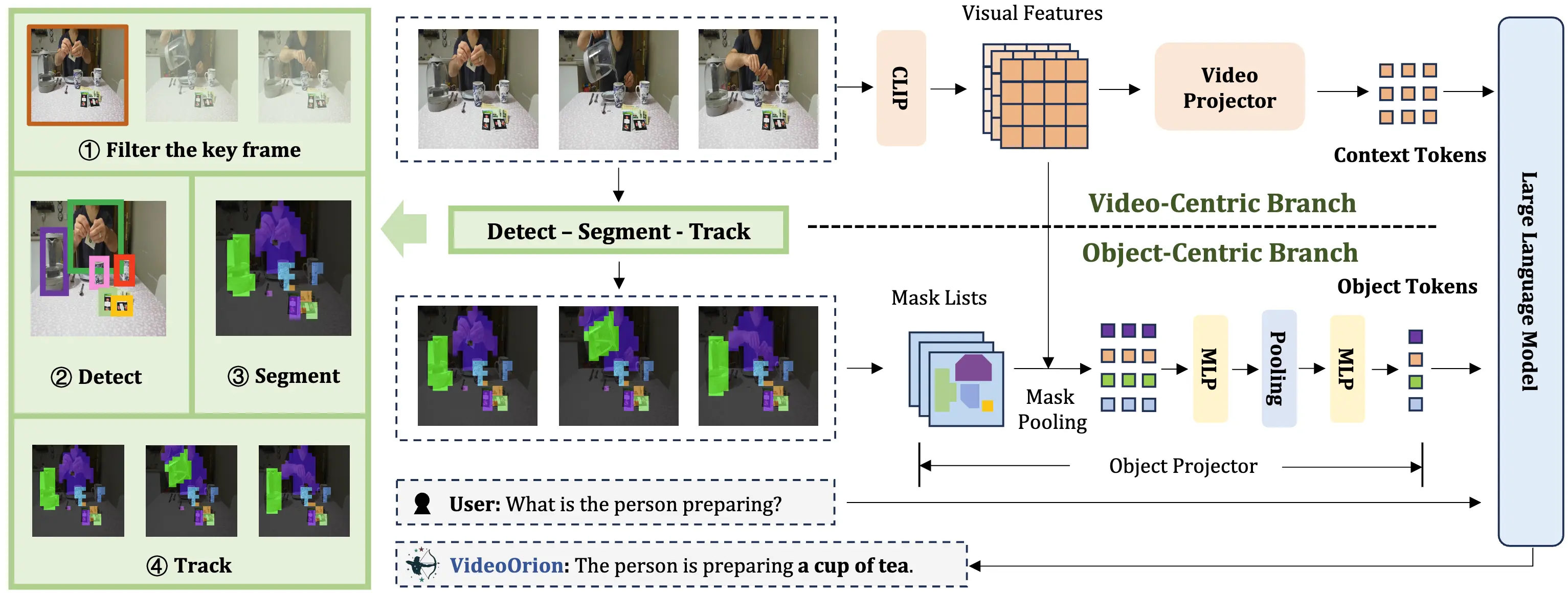
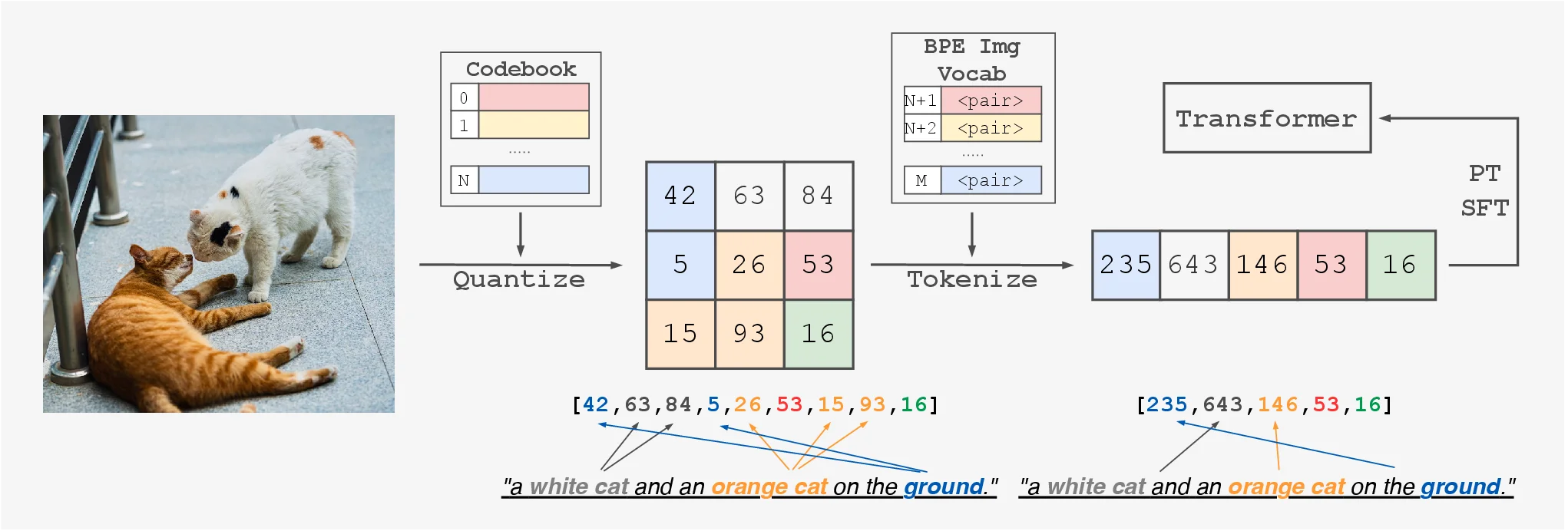
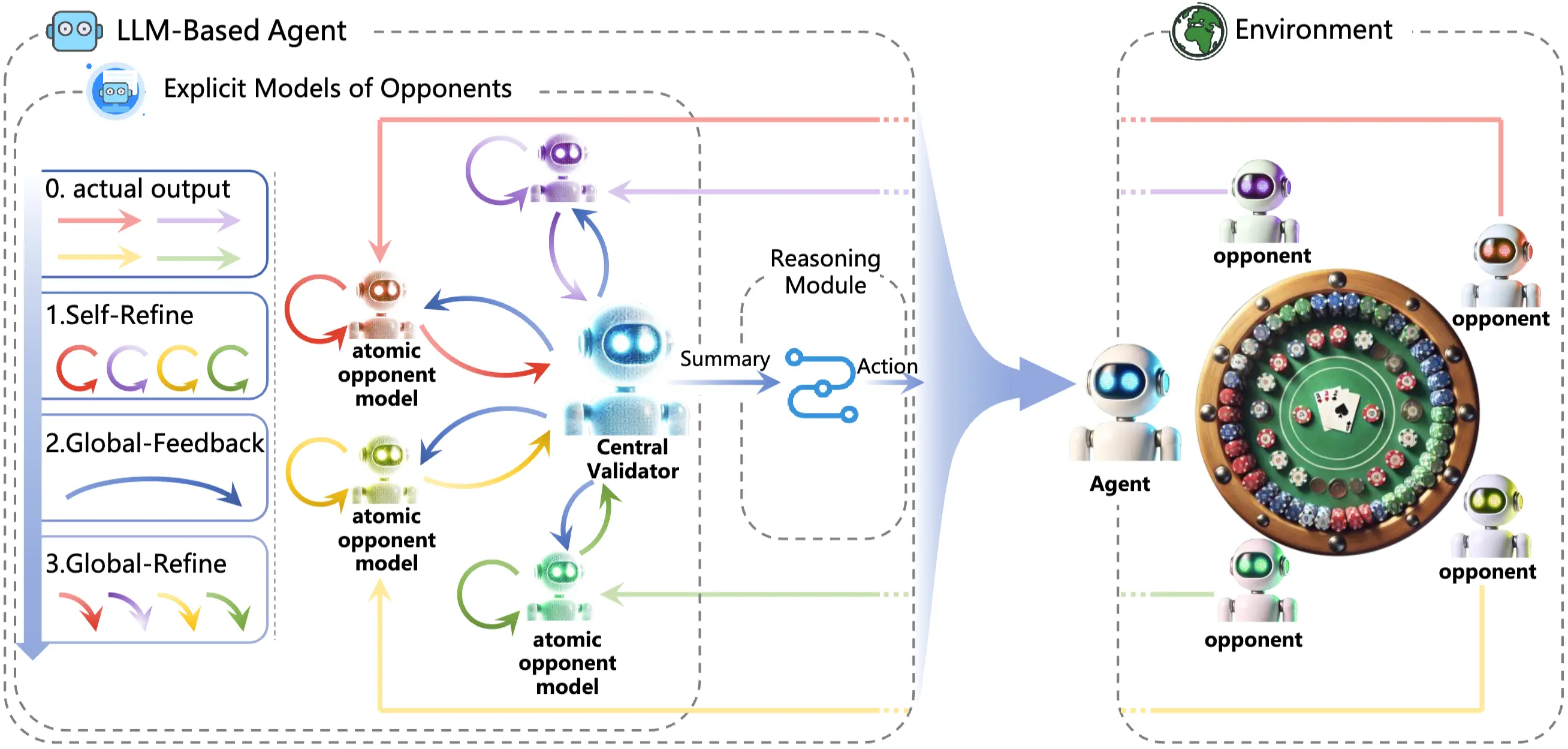
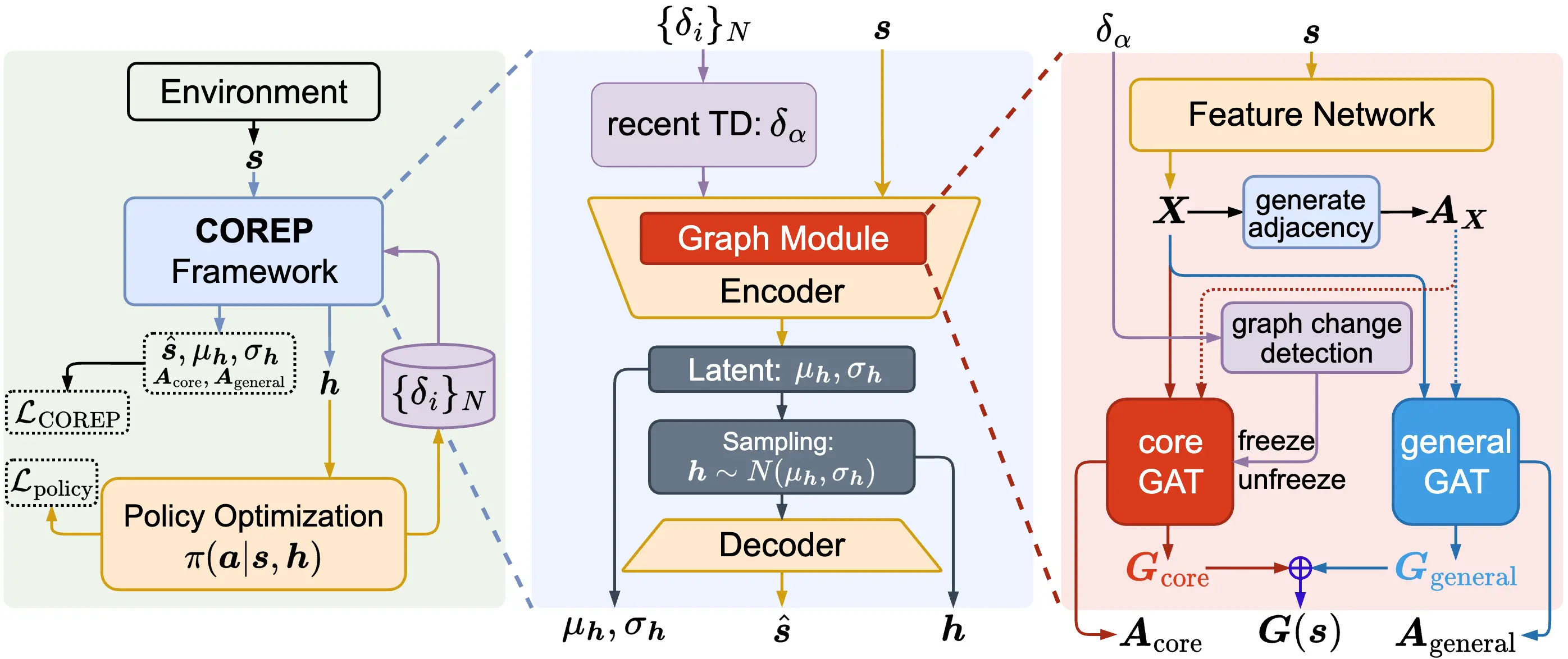
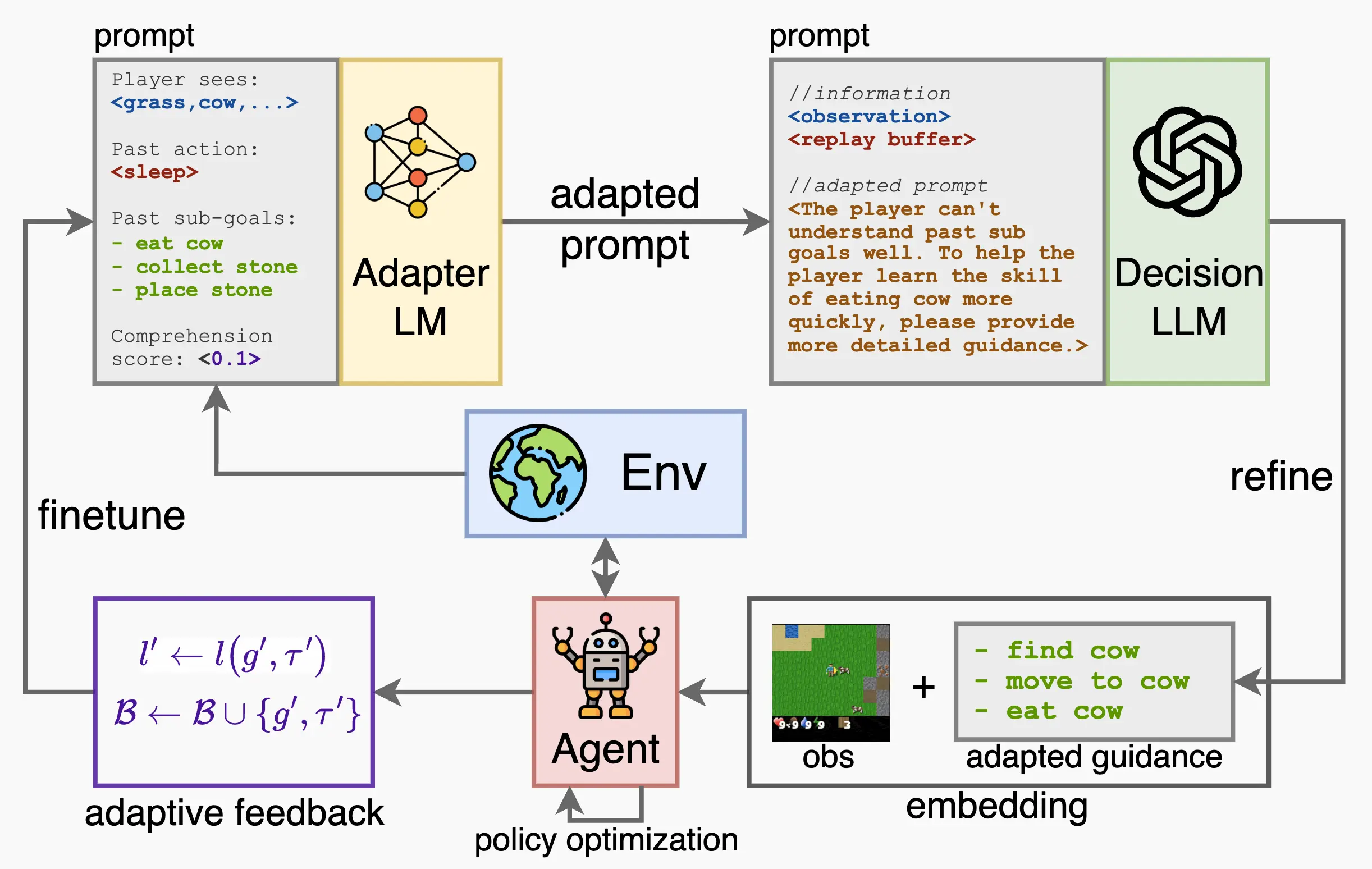
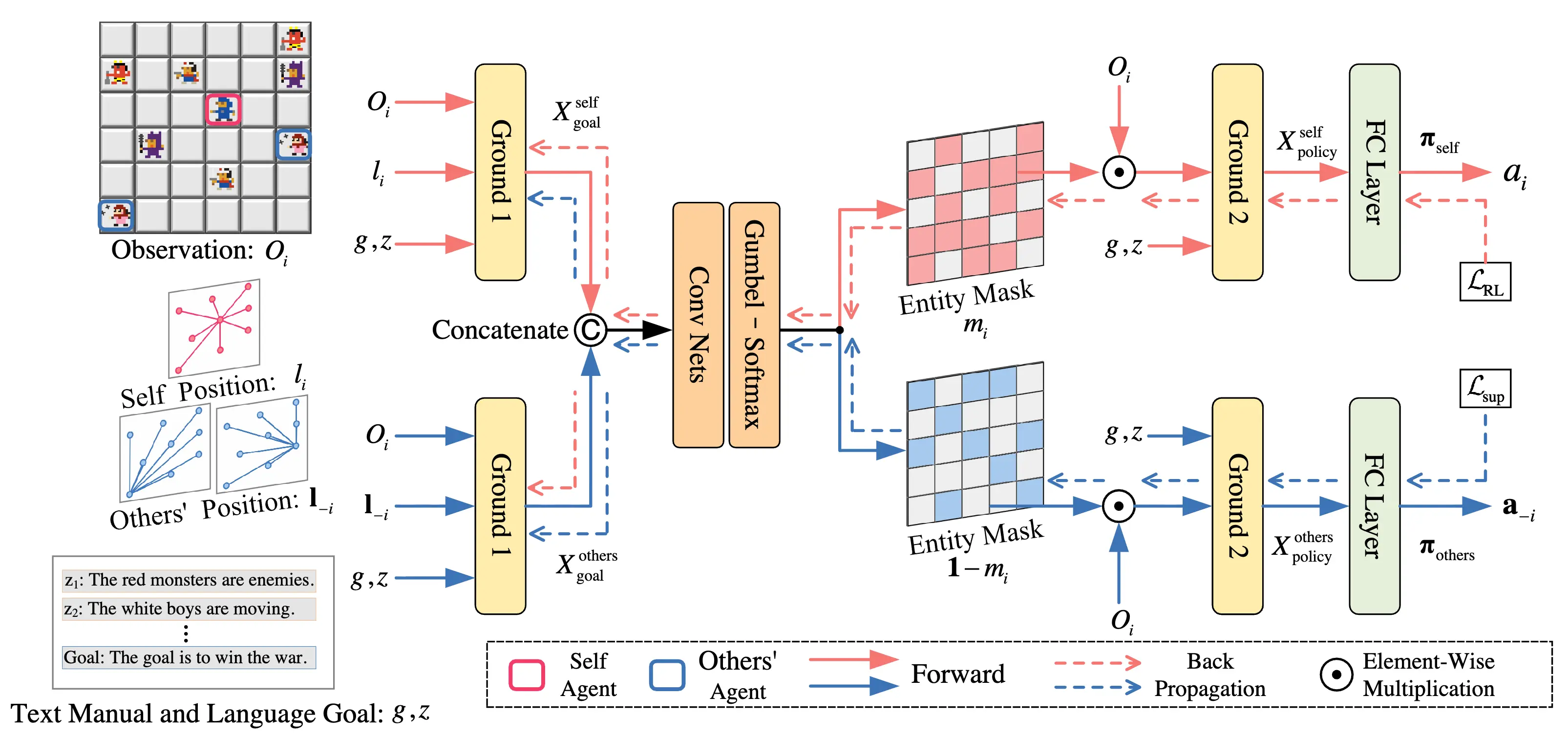
Education
- Peking University. (Beijing, China. Sep 2022 — Jun 2026)
- Ph.D. in Computer Science.
- Research Interest: Foundation Models / Reinforcement Learning / Robotics
- Tsinghua University. (Beijing, China. Sep 2019 — Jun 2022)
- M.S. in Computer Science.
- Research Interest: Reinforcement Learning
- Nankai University. (Tianjin, China. Sep 2015 — Jun 2019)
- B.S. in Mathematics.
- Research Interest: Mathematics / Machine Learning
Work Experience
- BeingBeyond. (Beijing, China. Mar 2025 — Present)
- Partner & Research Scientist.
- VLA / World Model / RL / Robotics
- Beijing Academy of Artificial Intelligence. (Beijing, China. May 2024 — Mar 2025)
- Research Intern.
- VLM / RL / Robotics
- Tencent AI Lab (Rhino-bird Program).
- Research Intern. (Shenzhen, China. Jun 2020 — Jul 2021)
- Reinforcement Learning
Patent
- Multimodal data processing method, device, storage medium, and electronic equipment. (CN119226992B)
- Zongqing Lu, Wanpeng Zhang.
- Link / PDF / Certificate
- Method, device and equipment for determining parameters and storage medium. (CN112527104A)
Award
- National Scholarship. (2025)
- Top 10 Students at the National Engineering Research Center of Visual Technology. (2025)
- Merit Student of Peking University. (2025)
- Presidential Scholarship of Peking University. (2024)
- Award for Scientific Research of Peking University. (2024)
- Rhino-bird Talent Program of Tencent. (2021)
- Mathematical Contest in Modeling (MCM/ICM), Meritorious Winner (First Prize). (2017)
- China Undergraduate Mathematical Contest in Modeling (CUMCM), Second Prize. (2016)
- National High School Mathematics Competition, Second Prize. (2014)
Service
- Conference Reviewer
- ICML / NeurIPS / ICLR / CVPR / ICCV / ECCV / ICRA / AAAI / AISTATS / BMVC
- Journal Reviewer
- TNNLS / TIST / RAL / TMLR
- Teaching Assistant
- Deep Reinforcement Learning, Peking University. (Spring, 2025)